#apache kafka training
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
Does Apache Kafka handle schema?
Apache Kafka does not natively handle schema enforcement or validation, but it provides a flexible and extensible architecture that allows users to implement schema management if needed. Kafka itself is a distributed streaming platform designed to handle large-scale event streaming and data integration, providing high throughput, fault tolerance, and scalability. While Kafka is primarily concerned with the storage and movement of data, it does not impose any strict schema requirements on the messages it processes. As a result, Kafka is often referred to as a "schema-agnostic" or "schema-less" system.
However, the lack of schema enforcement may lead to challenges when processing data from diverse sources or integrating with downstream systems that expect well-defined schemas. To address this, users often implement external schema management solutions or rely on schema serialization formats like Apache Avro, JSON Schema, or Protocol Buffers when producing and consuming data to impose a degree of structure on the data. Apart from it by obtaining Apache Kafka Certification, you can advance your career as a Apache Kafka. With this course, you can demonstrate your expertise in the basics of afka architecture, configuring Kafka cluster, working with Kafka APIs, performance tuning and, many more fundamental concepts.
By using these serialization formats and associated schema registries, producers can embed schema information into the messages they produce, allowing consumers to interpret the data correctly based on the schema information provided. Schema registries can store and manage the evolution of schemas, ensuring backward and forward compatibility when data formats change over time.
Moreover, some Kafka ecosystem tools and platforms, like Confluent Schema Registry, provide built-in support for schema management, making it easier to handle schema evolution, validation, and compatibility checks in a distributed and standardized manner. This enables developers to design robust, extensible, and interoperable data pipelines using Kafka, while also ensuring that data consistency and compatibility are maintained across the ecosystem. Overall, while Apache Kafka does not handle schema enforcement by default, it provides the flexibility and extensibility needed to incorporate schema management solutions that align with specific use cases and requirements.
0 notes
Text


This week was a productive one. I've been studying microservices to better understand distributed systems. At the bus company where I work, we use a monolithic system—an old-school setup style with MySQL, PHP, some Java applications, localhost server and a mix of other technologies. However, we've recently started implementing some features that require scalability, and this book has been instrumental in helping me understand the various scenarios involved.
In the first chapters, I've gained a clearer understanding of monolithic systems and the considerations for transitioning to a distributed system, including the pros and cons.
I've also been studying Java and Apache Kafka for event-driven architecture, a topic that has captured my full attention. In this case, the Confluent training platform offers excellent test labs, and I've been running numerous tests there. Additionally, I have my own Kafka cluster set up using Docker for most configurations.
With all that said, I've decided to update this blog weekly since daily updates it's not gonna work.
#coding#developer#linux#programming#programmer#software#software development#student#study blog#study aesthetic#studyblr#self improvement#study#software engineering#study motivation#studyblr community#studying#studynotes#learning#university#student life#university student#study inspiration#brazil#booklr#book#learn#self study#java#apachekafka
19 notes
·
View notes
Text
How can you optimize the performance of machine learning models in the cloud?
Optimizing machine learning models in the cloud involves several strategies to enhance performance and efficiency. Here’s a detailed approach:

Choose the Right Cloud Services:
Managed ML Services:
Use managed services like AWS SageMaker, Google AI Platform, or Azure Machine Learning, which offer built-in tools for training, tuning, and deploying models.
Auto-scaling:
Enable auto-scaling features to adjust resources based on demand, which helps manage costs and performance.
Optimize Data Handling:
Data Storage:
Use scalable cloud storage solutions like Amazon S3, Google Cloud Storage, or Azure Blob Storage for storing large datasets efficiently.
Data Pipeline:
Implement efficient data pipelines with tools like Apache Kafka or AWS Glue to manage and process large volumes of data.
Select Appropriate Computational Resources:
Instance Types:
Choose the right instance types based on your model’s requirements. For example, use GPU or TPU instances for deep learning tasks to accelerate training.
Spot Instances:
Utilize spot instances or preemptible VMs to reduce costs for non-time-sensitive tasks.
Optimize Model Training:
Hyperparameter Tuning:
Use cloud-based hyperparameter tuning services to automate the search for optimal model parameters. Services like Google Cloud AI Platform’s HyperTune or AWS SageMaker’s Automatic Model Tuning can help.
Distributed Training:
Distribute model training across multiple instances or nodes to speed up the process. Frameworks like TensorFlow and PyTorch support distributed training and can take advantage of cloud resources.
Monitoring and Logging:
Monitoring Tools:
Implement monitoring tools to track performance metrics and resource usage. AWS CloudWatch, Google Cloud Monitoring, and Azure Monitor offer real-time insights.
Logging:
Maintain detailed logs for debugging and performance analysis, using tools like AWS CloudTrail or Google Cloud Logging.
Model Deployment:
Serverless Deployment:
Use serverless options to simplify scaling and reduce infrastructure management. Services like AWS Lambda or Google Cloud Functions can handle inference tasks without managing servers.
Model Optimization:
Optimize models by compressing them or using model distillation techniques to reduce inference time and improve latency.
Cost Management:
Cost Analysis:
Regularly analyze and optimize cloud costs to avoid overspending. Tools like AWS Cost Explorer, Google Cloud’s Cost Management, and Azure Cost Management can help monitor and manage expenses.
By carefully selecting cloud services, optimizing data handling and training processes, and monitoring performance, you can efficiently manage and improve machine learning models in the cloud.
2 notes
·
View notes
Text
Data Science
📌Data scientists use a variety of tools and technologies to help them collect, process, analyze, and visualize data. Here are some of the most common tools that data scientists use:
👩🏻💻Programming languages: Data scientists typically use programming languages such as Python, R, and SQL for data analysis and machine learning.
📊Data visualization tools: Tools such as Tableau, Power BI, and matplotlib allow data scientists to create visualizations that help them better understand and communicate their findings.
🛢Big data technologies: Data scientists often work with large datasets, so they use technologies like Hadoop, Spark, and Apache Cassandra to manage and process big data.
🧮Machine learning frameworks: Machine learning frameworks like TensorFlow, PyTorch, and scikit-learn provide data scientists with tools to build and train machine learning models.
☁️Cloud platforms: Cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure provide data scientists with access to powerful computing resources and tools for data processing and analysis.
📌Data management tools: Tools like Apache Kafka and Apache NiFi allow data scientists to manage data pipelines and automate data ingestion and processing.
🧹Data cleaning tools: Data scientists use tools like OpenRefine and Trifacta to clean and preprocess data before analysis.
☎️Collaboration tools: Data scientists often work in teams, so they use tools like GitHub and Jupyter Notebook to collaborate and share code and analysis.
For more follow @woman.engineer
#google#programmers#coding#coding is fun#python#programminglanguage#programming#woman engineer#zeynep küçük#yazılım#coder#tech
25 notes
·
View notes
Text
Best Data Science Institute in Delhi: Top Courses & Career Opportunities

Why Data Science is Booming?
Data is shaping the world like never before. From personalized Netflix recommendations to fraud detection in banking, data science is driving major decisions across industries. Companies rely on data experts to analyze trends, improve efficiency, and boost profits.
The Rising Demand for Data Science Professionals
The demand for skilled data scientists is skyrocketing. Reports show that India has over 90,000+ job openings in this field. Top companies like Google, Amazon, and TCS actively hire data professionals with the right skills. The global data science market is projected to reach $322 billion by 2026, making it one of the fastest-growing career paths.
Choosing the Right Data Science Institute
Many aspirants struggle to find the best data science institute in Delhi. With so many options, it’s tough to pick a reliable and industry-focused institute that provides: ✔ Practical hands-on training ✔ Expert mentorship ✔ 100% placement assistance
Why Modulating Digital Institute?
If you are looking for a career-focused and skill-driven learning experience, Modulating Digital Institute is your perfect choice. With real-world projects, top-notch faculty, and placement support, this institute ensures you step into the data science world fully prepared.
Want to build a successful career in data science? Keep reading to find out how!
Why Learn Data Science?
Data Science: The Future of Innovation
Data is at the core of every industry today. Businesses, healthcare, finance, and even entertainment rely on data-driven insights to make smart decisions. Data science professionals help organizations analyze trends, predict outcomes, and optimize processes, making their skills highly valuable in today’s job market.
If you’re considering a career in this field, choosing the best data science institute in Delhi is crucial. The right training can equip you with the skills needed to thrive in this ever-growing industry.
High Demand Across Industries
Data science is not limited to IT. It plays a significant role in multiple sectors:
Healthcare: Predicting diseases, analyzing patient data, and personalizing treatments
.Finance & Banking: Fraud detection, algorithmic trading, and risk assessment.
E-commerce & Retail: Customer behavior analysis and recommendation engines.
Marketing & Advertising: Data-driven campaign optimization and audience targeting.
Manufacturing: Quality control, predictive maintenance, and automation.
With such vast applications, the demand for skilled data professionals continues to grow rapidly.
Job Growth & Career Opportunities
India is among the top countries where data science jobs are increasing rapidly. According to NASSCOM, the demand for data professionals has grown by 40% in the last five years.
Here’s a look at some of the top career opportunities in data science and their average salaries in India:
Job Role
Average Salary (INR)
Experience Level
Data Scientist
₹10-15 LPA
Entry-Level
Machine Learning Engineer
₹12-18 LPA
Mid-Level
Big Data Engineer
₹10-16 LPA
Mid-Level
Business Intelligence Analyst
₹6-10 LPA
Entry-Level
AI Engineer
₹15-25 LPA
Senior-Level
Data Analyst
₹6-9 LPA
Entry-Level
Skills Required to Become a Data Science Professional
To succeed in this field, mastering the right tools and skills is essential. Any top data science institute in Delhi should train students in:
Programming Languages: Python, R, SQL
Machine Learning & AI: Neural networks, deep learning, NLP
Big Data Technologies: Hadoop, Spark, Apache Kafka
Data Visualization: Tableau, Power BI, Excel Analytics
Cloud Computing: AWS, Azure, Google Cloud
Mathematics & Statistics: Probability, linear algebra, data modeling
Why Enroll in the Best Data Science Institute in Delhi?
Learning data science from an industry-focused institute can boost your career prospects significantly. A comprehensive and practical curriculum will ensure you gain:
✔ Hands-on training with real-world datasets ✔ Expert mentorship from industry professionals ✔ Job placement support with top companies
Finding the right institute can make a huge difference in your learning experience and career success. This is where Modulating Digital Institute stands out.
With real-world projects, top faculty, and placement assistance, Modulating Digital Institute ensures that students are job-ready by the time they complete their training.
If you’re serious about becoming a data science expert, investing in the best data science institute in Delhi will be the smartest career move.
How to Choose the Best Data Science Institute in Delhi?
Why Choosing the Right Institute Matters?
With the increasing demand for data scientists, many training institutes claim to offer the best data science courses. However, not all provide practical learning, industry exposure, and career support. Choosing the best data science institute in Delhi can make a significant difference in your skills, job readiness, and salary prospects.
Here are the key factors to consider when selecting a top data science institute:
1. Comprehensive & Industry-Relevant Curriculum
A well-structured curriculum is essential for building a strong foundation in data science. The best data science training should cover:
Programming Languages: Python, R, SQL – for data analysis and machine learning.
Machine Learning & AI: Deep learning, NLP, neural networks.
Big Data Technologies: Hadoop, Spark – for handling large datasets.
Data Visualization: Tableau, Power BI – to create insights-driven reports.
Statistics & Mathematics: Probability, regression analysis – to understand data trends.
Real-World Projects: Hands-on experience with live case studies.
2. Hands-On Training & Live Industry Projects
Learning theoretical concepts is not enough to become a data science professional. A top data science institute in Delhi should offer:
✔ Practical exposure with live datasets ✔ Real-world case studies from different industries ✔ Capstone projects based on actual business problems
Institutes that provide hands-on experience help students develop problem-solving skills required in real job scenarios.
3. Experienced Faculty & One-on-One Mentorship
Having the right mentor can accelerate your learning process. Choose an institute where:
Trainers have real industry experience in data science, AI, and machine learning.
There are guest lectures from professionals working in companies like Google, Amazon, and TCS.
One-on-one mentorship is available to solve doubts and guide career growth.
4. Placement Support & Industry Connections
A data science course should not only focus on training but also on career growth. Before enrolling, check if the institute provides:
100% placement assistance with resume-building workshops.
Mock interviews and career counseling sessions.
Industry tie-ups with top companies for job referrals.
Best Data Science Institute in Delhi – Why Modulating Digital Institute?
When it comes to choosing the best data science institute in Delhi, it’s essential to look beyond the curriculum. The right institute should not only provide theoretical knowledge but also hands-on training, industry exposure, and placement support. Here’s why Modulating Digital Institute stands out as the top choice for aspiring data science professionals:
Industry-Aligned Curriculum
At Modulating Digital Institute, the curriculum is designed to ensure you gain practical knowledge that is directly applicable in the industry. The institute offers: 📌 Core Subjects – Python, R, SQL, Machine Learning, Data Visualization, Big Data, and AI. 📌 Advanced Topics – Deep Learning, NLP, Cloud Computing, Data Engineering. 📌 Real-World Projects – You’ll work on live datasets, case studies, and business problems faced by leading companies. This hands-on experience makes you job-ready.
This focus on real-world applicability ensures you are not just learning concepts but gaining the skills that employers demand.
Expert Trainers and Mentorship
Learning from industry experts is one of the key advantages of Modulating Digital Institute. The faculty consists of seasoned professionals who have worked in top companies like Google, Amazon, and Microsoft. They bring industry insights, helping you understand the practical applications of data science. Furthermore, you will receive one-on-one mentorship, guiding you through your learning journey and helping you tackle any challenges.
Placement Support and Job Assistance
One of the biggest concerns for data science aspirants is landing a job after completing their course. Modulating Digital Institute solves this challenge by offering: ✅ Resume-building workshops and mock interviews. ✅ Job placement assistance, with connections to top companies in tech, finance, healthcare, and more. ✅ Internships and live project opportunities to give you a foothold in the industry.
By focusing on employability, Modulating Digital Institute ensures that you are ready to enter the competitive job market as a highly skilled data scientist.
Affordable and Flexible Learning Options
Modulating Digital Institute offers a wide range of learning options to suit your schedule and budget: 📌 Online and Offline Classes – Whether you prefer in-person learning or studying from home, the institute offers flexible options. 📌 Affordable Fees – Compared to other institutes in Delhi, Modulating Digital Institute provides high-quality training at a competitive price. 📌 EMI Options – For students who need financial flexibility, EMI options are available to ease the payment process.
Why Modulating Digital Institute is the Best Data Science Institute in Delhi?
With an industry-aligned curriculum, hands-on training, expert mentors, and strong placement support, Modulating Digital Institute is the best choice for anyone looking to start a career in data science. Choosing the best data science institute in Delhi is an important decision, and with Modulating Digital Institute, you’re setting yourself up for success. Whether you're just starting or looking to upskill, this institute offers everything you need to excel in the world of data science.
Job Roles & Career Opportunities After Data Science Training
Exploring Career Paths in Data Science
Data science opens up a world of career opportunities. With the skills learned at the best data science institute in Delhi, you can pursue various roles across different industries. Whether it’s analyzing data to derive insights, building machine learning models, or managing big data, data science has something for everyone. Let’s look at some of the key job roles in data science and their corresponding average salaries in India.
1. Data Scientist
As the core of any data science team, a Data Scientist is responsible for analyzing large datasets, building machine learning models, and providing actionable insights. Their role is to create predictive models, uncover hidden patterns, and use algorithms to drive business decisions. Average Salary: ₹10-15 LPA Skills Needed: Python, R, Machine Learning, Data Visualization, SQL
2. Machine Learning Engineer
A Machine Learning Engineer builds and deploys machine learning models, helping businesses make decisions based on predictions and patterns. They work closely with data scientists but focus more on the engineering and implementation side of machine learning. Average Salary: ₹12-18 LPA Skills Needed: Python, TensorFlow, Deep Learning, Data Engineering, Cloud Computing
3. Data Analyst
A Data Analyst focuses on gathering and analyzing data, then using data visualization tools to present actionable insights. While their role is more analytical than predictive, data analysts play a key role in making sense of data for business use. Average Salary: ₹6-9 LPA Skills Needed: Excel, SQL, Tableau, Power BI, Data Visualization
4. Business Intelligence (BI) Analyst
A Business Intelligence Analyst uses data to provide business insights, helping management make informed decisions. They focus on gathering data from various sources, creating reports, and analyzing trends to inform strategic business plans. Average Salary: ₹6-10 LPA Skills Needed: SQL, Power BI, Tableau, Data Warehousing, Reporting
5. Big Data Engineer
Big Data Engineers handle massive datasets using specialized technologies. They build systems that process large volumes of data and ensure the smooth functioning of big data platforms. Their job is crucial for organizations dealing with petabytes of data. Average Salary: ₹10-16 LPA Skills Needed: Hadoop, Spark, Kafka, NoSQL, Data Warehousing
6. Data Engineer
A Data Engineer focuses on building and maintaining the infrastructure that allows data scientists and analysts to work with data. They design, construct, and optimize data pipelines, ensuring the data is structured and easily accessible. Average Salary: ₹8-14 LPA Skills Needed: Python, SQL, ETL, Data Warehousing, Cloud Platforms
7. AI Engineer
An AI Engineer specializes in building artificial intelligence systems that mimic human behavior. They develop intelligent systems such as chatbots, recommendation engines, and self-driving cars. Average Salary: ₹15-25 LPA Skills Needed: Python, TensorFlow, NLP, Deep Learning, AI Algorithms
8. Data Architect
A Data Architect designs and manages the systems and databases that store and organize data. They focus on creating efficient databases and ensuring data is stored securely and can be easily accessed. Average Salary: ₹15-20 LPA Skills Needed: SQL, Database Management, Cloud Computing, Data Modeling
Why Modulating Digital Institute is Your Gateway to These Careers?
The best data science institute in Delhi, like Modulating Digital Institute, offers tailored training to help you pursue any of these roles. Through expert-led courses and hands-on experience, you’ll acquire the necessary skills and knowledge for these positions.
With modular courses, industry-relevant projects, and placement assistance, Modulating Digital Institute ensures you are job-ready from day one. Whether you aspire to be a data scientist, machine learning engineer, or big data expert, the institute will provide you with the tools you need to succeed.
Don’t just dream of a career in data science—take the first step by joining the best data science institute in Delhi!
Tools and Technologies You Will Learn in Data Science
Essential Tools for Data Science Professionals
Data science is a multi-faceted discipline, and the best data scientists are proficient in a wide array of tools and technologies. The best data science institute in Delhi should train you in industry-standard tools that will help you analyze, visualize, and build models efficiently. Let’s take a closer look at the most popular tools and technologies used in data science and how they contribute to the data science workflow.
1. Python
Python is the go-to programming language for data science due to its simplicity and extensive libraries. Whether it’s data manipulation, visualization, or machine learning, Python is the primary language used by data scientists around the world. Popular Libraries: Pandas, NumPy, Scikit-learn, Matplotlib, Seaborn. Skills Learned: Data manipulation, machine learning, data visualization, and deep learning.
2. R
R is another powerful language used for statistical analysis and data visualization. It’s particularly popular among statisticians and data analysts who need to perform complex statistical computations. Popular Libraries: ggplot2, dplyr, caret, Shiny. Skills Learned: Statistical analysis, hypothesis testing, data visualization.
3. SQL
SQL (Structured Query Language) is essential for interacting with databases. Data scientists use SQL to retrieve, manipulate, and manage data stored in relational databases. Skills Learned: Querying databases, data extraction, database management.
4. Machine Learning Frameworks
Machine learning is a key component of data science. Familiarity with machine learning frameworks
Tools and Technologies You Will Learn at the Best Data Science Institute in Delhi
Importance of Tools in Data Science
In the world of data science, having the right tools and technologies is essential to solving problems, analyzing data, and building models efficiently. At the best data science institute in Delhi, students learn to master the most widely used tools that are integral to a career in data science. These tools help streamline processes, making data handling and analysis faster and more effective.
Here’s a breakdown of the key tools and technologies you will learn during your training:
1. Python
Python is the most popular programming language in data science due to its simplicity and rich libraries. It’s the go-to language for building algorithms, analyzing datasets, and developing machine learning models. Key Libraries: Pandas, NumPy, Scikit-learn, TensorFlow, Keras, Matplotlib Why Learn Python? Python is versatile and used in data analysis, machine learning, data visualization, and even deep learning. Learning Python at the best data science institute in Delhi opens doors to a wide range of job roles.
2. R
R is another important programming language used for statistical analysis and data visualization. It’s especially popular in
How Modulating Digital Institute Prepares You for a Successful Data Science Career
Industry-Focused Curriculum and Real-World Projects
At the best data science institute in Delhi, it’s essential to receive a comprehensive, industry-aligned curriculum that goes beyond theoretical knowledge. Modulating Digital Institute offers a robust course that provides both the fundamentals and advanced topics in data science. Through real-world projects, you will:
✔ Work with live datasets from industries such as healthcare, finance, and e-commerce. ✔ Solve actual business problems faced by companies, gaining practical experience. ✔ Develop hands-on expertise in machine learning, big data, and data visualization tools.
These practical projects will help you build a portfolio that stands out to employers and gives you an edge in the job market.
Expert Mentors with Industry Experience
Learning from experienced professionals is crucial for success in the data science field. Modulating Digital Institute has a team of industry experts who bring real-world experience into the classroom. They will:
✔ Provide personalized mentorship to guide your learning and career path. ✔ Share industry insights, making you aware of the latest trends and tools in data science. ✔ Help you develop critical thinking and problem-solving skills, ensuring you are job-ready from day one.
Hands-On Training with Industry-Standard Tools
The right tools are essential for becoming a successful data scientist. Modulating Digital Institute ensures you get hands-on experience with the industry-standard tools used in the field, including:
📌 Python & R for data manipulation and analysis 📌 SQL for database management 📌 Machine Learning frameworks like Scikit-learn, TensorFlow, and Keras 📌 Big Data Technologies like Hadoop, Spark, and Kafka 📌 Data Visualization tools such as Tableau, Power BI, and Matplotlib
With these tools in your toolkit, you'll be equipped to handle complex data science challenges across any industry.
Placement Support & Career Guidance
Securing a job after completing your course is one of the primary goals, and Modulating Digital Institute prioritizes career placement. The institute offers:
✅ Job Placement Assistance – with connections to top companies in tech, finance, healthcare, and more. ✅ Mock Interviews – preparing you for real-world job interviews with industry recruiters. ✅ Resume Building – helping you craft a professional resume that highlights your skills and projects. ✅ Job Referral Support – helping you access exclusive job opportunities with partner companies.
With 100% placement support, Modulating Digital Institute ensures that you don’t just finish a course—you launch your career in data science.
Why Choose Modulating Digital Institute?
Choosing the best data science institute in Delhi is a critical decision, and Modulating Digital Institute offers everything you need for a successful career in data science:
✔ Industry-aligned curriculum with real-world exposure. ✔ Experienced mentors to guide you through every step of your learning journey. ✔ Hands-on training in the most popular data science tools. ✔ Comprehensive placement support to help you land your first data science job.
With Modulating Digital Institute, you’ll not only gain the knowledge and skills needed to excel in data science but also the practical experience and job support to ensure your success. Take the first step towards a fulfilling career in data science by enrolling today!
#DataScience#CareerInDataScience#ModulatingDigitalInstitute#BestDataScienceInstitute#DataScienceSkills#CareerOpportunities#JobRoles#DataScienceTraining#Upskill#FutureInDataScience
0 notes
Text
What is the cost of a data science course in Bangalore?
Data Science Classes in Bangalore – A Complete Guide
Bangalore, often referred to as the Silicon Valley of India, is a thriving hub for technology and innovation. With the increasing demand for data-driven decision-making across industries, learning Data Science has become a top priority for students and professionals alike. If you are looking for the best Data Science Classes in Bangalore, this guide will provide detailed insights into course structures, costs, career opportunities, and factors to consider when choosing an institute.

What is Data Science?
Data Science is an interdisciplinary field that uses statistics, machine learning, artificial intelligence, and programming to extract meaningful insights from large datasets. It helps businesses make informed decisions, optimize operations, and predict future trends.
Key Components of Data Science:
Data Collection & Cleaning: Gathering raw data and preparing it for analysis.
Exploratory Data Analysis (EDA): Understanding data patterns and relationships.
Machine Learning: Training algorithms to identify patterns and make predictions.
Data Visualization: Representing data insights using graphs and charts.
Big Data Technologies: Managing large-scale datasets using tools like Hadoop and Spark.
Statistical Analysis: Applying probability and statistics for data interpretation.
Why Learn Data Science?
1. High Demand for Data Professionals
Companies worldwide are leveraging data science to improve efficiency and drive business growth. This has created a massive demand for skilled professionals in various sectors, including finance, healthcare, retail, and IT.
2. Lucrative Career Opportunities
Data science professionals command some of the highest salaries in the industry. A skilled data scientist can earn between ₹5-8 LPA (entry-level), ₹10-15 LPA (mid-level), and over ₹20 LPA (senior-level) in India.
3. Diverse Career Paths
Completing a Data Science Course in Bangalore opens doors to multiple career roles:
Data Scientist – Develops models and analyzes data to solve business problems.
Data Analyst – Focuses on interpreting structured data and creating reports.
Machine Learning Engineer – Builds AI-powered models for automation and prediction.
Business Intelligence Analyst – Transforms raw data into actionable insights.
What to Expect from Data Science Classes in Bangalore?
1. Course Curriculum
A well-structured Data Science Course in Bangalore should cover theoretical knowledge and practical applications. Here are the key topics:
Programming Languages: Python, R, SQL
Data Manipulation & Processing: Pandas, NumPy
Machine Learning Algorithms: Supervised & Unsupervised Learning
Deep Learning & Artificial Intelligence: Neural Networks, TensorFlow, Keras
Big Data Technologies: Hadoop, Spark, Apache Kafka
Statistical Analysis & Probability: Regression, Hypothesis Testing
Data Visualization Tools: Tableau, Power BI, Matplotlib
Real-World Projects & Case Studies: Hands-on experience in solving business problems
2. Course Duration
Depending on your expertise level, you can choose from:
Short-Term Courses (2-3 months): Covers fundamental concepts, suitable for beginners.
Advanced Courses (6-12 months): Provides deeper insights with hands-on projects.
Postgraduate & Certification Programs: Offered by universities and professional institutes.
3. Learning Modes
Bangalore offers various learning modes to suit different preferences:
Classroom Training: Provides hands-on experience and networking opportunities.
Online Learning: Best for working professionals who need flexibility.
Hybrid Learning: A combination of online theory and offline practical sessions.
Best Data Science Classes in Bangalore
If you are looking for the best Data Science Classes in Bangalore, choosing the right institute is crucial. Many institutes offer Data Science Courses in Bangalore, but selecting the right one depends on factors like course content, industry exposure, and placement assistance.
Kodestree provides a comprehensive Data Science Course in Bangalore that covers practical projects, expert mentoring, and placement support to help students secure jobs in leading companies.
Factors to Consider When Choosing a Data Science Course
Comprehensive Curriculum: Ensure that the course covers all essential topics.
Hands-On Training: Real-world projects are crucial for gaining practical experience.
Industry Recognition: Choose an institute with a strong reputation.
Placement Support: Institutes with job assistance increase your hiring chances.
Affordability: Compare course fees and ensure quality training at a reasonable price.
Data Science Course Fees in Bangalore
The cost of Data Science Classes in Bangalore varies based on course duration, mode of learning, and institute reputation. Here is a rough estimate:
Basic Certificate Courses: ₹15,000 - ₹50,000
Advanced Data Science Programs: ₹50,000 - ₹1,50,000
Postgraduate & Master’s Programs: ₹2,00,000 - ₹5,00,000
Kodestree offers a well-structured Data Science Course in Bangalore at an affordable fee, making it accessible to students and professionals looking for a career switch.
Career Opportunities After Completing Data Science Classes in Bangalore
Once you complete a Data Science Course in Bangalore, you can explore various job opportunities in Bangalore’s IT and business ecosystem. Companies across sectors like finance, healthcare, e-commerce, and IT actively hire data science professionals.
Top Career Roles in Data Science:
Data Scientist – Uses machine learning models to analyze large datasets.
Data Analyst – Works with structured data to generate business insights.
Machine Learning Engineer – Develops and deploys AI-based applications.
Business Intelligence Analyst – Helps businesses make data-driven decisions.
Salary Expectations
Entry-Level (0-2 years): ₹5-8 LPA
Mid-Level (3-5 years): ₹10-15 LPA
Senior-Level (5+ years): ₹20+ LPA
Who Should Enroll in Data Science Classes in Bangalore?
Students & Graduates: Those looking to build a career in data science.
IT Professionals: Software engineers and IT experts wanting to upskill.
Business Analysts: Professionals looking to enhance analytical skills.
Entrepreneurs & Startups: Business owners wanting to leverage data science for growth.
Final Thoughts
Bangalore is one of the best cities to pursue a career in data science, with numerous institutes offering specialized training. If you're looking for Data Science Classes in Bangalore, Kodestree provides an industry-relevant Data Science Course in Bangalore with Placement to help students and professionals advance their careers.
Enrolling in a Data Science Course in Bangalore can be the first step toward a high-paying and rewarding career. Choose the right institute, gain hands-on experience, and build a successful future in data science. Start your journey today!
0 notes
Text
AWS Data Analytics Training | AWS Data Engineering Training in Bangalore
What’s the Most Efficient Way to Ingest Real-Time Data Using AWS?
AWS provides a suite of services designed to handle high-velocity, real-time data ingestion efficiently. In this article, we explore the best approaches and services AWS offers to build a scalable, real-time data ingestion pipeline.

Understanding Real-Time Data Ingestion
Real-time data ingestion involves capturing, processing, and storing data as it is generated, with minimal latency. This is essential for applications like fraud detection, IoT monitoring, live analytics, and real-time dashboards. AWS Data Engineering Course
Key Challenges in Real-Time Data Ingestion
Scalability – Handling large volumes of streaming data without performance degradation.
Latency – Ensuring minimal delay in data processing and ingestion.
Data Durability – Preventing data loss and ensuring reliability.
Cost Optimization – Managing costs while maintaining high throughput.
Security – Protecting data in transit and at rest.
AWS Services for Real-Time Data Ingestion
1. Amazon Kinesis
Kinesis Data Streams (KDS): A highly scalable service for ingesting real-time streaming data from various sources.
Kinesis Data Firehose: A fully managed service that delivers streaming data to destinations like S3, Redshift, or OpenSearch Service.
Kinesis Data Analytics: A service for processing and analyzing streaming data using SQL.
Use Case: Ideal for processing logs, telemetry data, clickstreams, and IoT data.
2. AWS Managed Kafka (Amazon MSK)
Amazon MSK provides a fully managed Apache Kafka service, allowing seamless data streaming and ingestion at scale.
Use Case: Suitable for applications requiring low-latency event streaming, message brokering, and high availability.
3. AWS IoT Core
For IoT applications, AWS IoT Core enables secure and scalable real-time ingestion of data from connected devices.
Use Case: Best for real-time telemetry, device status monitoring, and sensor data streaming.
4. Amazon S3 with Event Notifications
Amazon S3 can be used as a real-time ingestion target when paired with event notifications, triggering AWS Lambda, SNS, or SQS to process newly added data.
Use Case: Ideal for ingesting and processing batch data with near real-time updates.
5. AWS Lambda for Event-Driven Processing
AWS Lambda can process incoming data in real-time by responding to events from Kinesis, S3, DynamoDB Streams, and more. AWS Data Engineer certification
Use Case: Best for serverless event processing without managing infrastructure.
6. Amazon DynamoDB Streams
DynamoDB Streams captures real-time changes to a DynamoDB table and can integrate with AWS Lambda for further processing.
Use Case: Effective for real-time notifications, analytics, and microservices.
Building an Efficient AWS Real-Time Data Ingestion Pipeline
Step 1: Identify Data Sources and Requirements
Determine the data sources (IoT devices, logs, web applications, etc.).
Define latency requirements (milliseconds, seconds, or near real-time?).
Understand data volume and processing needs.
Step 2: Choose the Right AWS Service
For high-throughput, scalable ingestion → Amazon Kinesis or MSK.
For IoT data ingestion → AWS IoT Core.
For event-driven processing → Lambda with DynamoDB Streams or S3 Events.
Step 3: Implement Real-Time Processing and Transformation
Use Kinesis Data Analytics or AWS Lambda to filter, transform, and analyze data.
Store processed data in Amazon S3, Redshift, or OpenSearch Service for further analysis.
Step 4: Optimize for Performance and Cost
Enable auto-scaling in Kinesis or MSK to handle traffic spikes.
Use Kinesis Firehose to buffer and batch data before storing it in S3, reducing costs.
Implement data compression and partitioning strategies in storage. AWS Data Engineering online training
Step 5: Secure and Monitor the Pipeline
Use AWS Identity and Access Management (IAM) for fine-grained access control.
Monitor ingestion performance with Amazon CloudWatch and AWS X-Ray.
Best Practices for AWS Real-Time Data Ingestion
Choose the Right Service: Select an AWS service that aligns with your data velocity and business needs.
Use Serverless Architectures: Reduce operational overhead with Lambda and managed services like Kinesis Firehose.
Enable Auto-Scaling: Ensure scalability by using Kinesis auto-scaling and Kafka partitioning.
Minimize Costs: Optimize data batching, compression, and retention policies.
Ensure Security and Compliance: Implement encryption, access controls, and AWS security best practices. AWS Data Engineer online course
Conclusion
AWS provides a comprehensive set of services to efficiently ingest real-time data for various use cases, from IoT applications to big data analytics. By leveraging Amazon Kinesis, AWS IoT Core, MSK, Lambda, and DynamoDB Streams, businesses can build scalable, low-latency, and cost-effective data pipelines. The key to success is choosing the right services, optimizing performance, and ensuring security to handle real-time data ingestion effectively.
Would you like more details on a specific AWS service or implementation example? Let me know!
Visualpath is Leading Best AWS Data Engineering training.Get an offering Data Engineering course in Hyderabad.With experienced,real-time trainers.And real-time projects to help students gain practical skills and interview skills.We are providing 24/7 Access to Recorded Sessions ,For more information,call on +91-7032290546
For more information About AWS Data Engineering training
Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-aws-data-engineering-course.html
#AWS Data Engineering Course#AWS Data Engineering training#AWS Data Engineer certification#Data Engineering course in Hyderabad#AWS Data Engineering online training#AWS Data Engineering Training Institute#AWS Data Engineering training in Hyderabad#AWS Data Engineer online course#AWS Data Engineering Training in Bangalore#AWS Data Engineering Online Course in Ameerpet#AWS Data Engineering Online Course in India#AWS Data Engineering Training in Chennai#AWS Data Analytics Training
0 notes
Text
Explore how ADF integrates with Azure Synapse for big data processing.
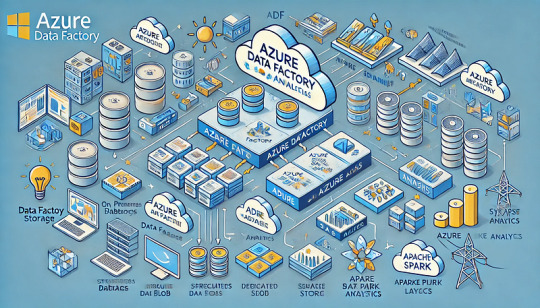
How Azure Data Factory (ADF) Integrates with Azure Synapse for Big Data Processing
Azure Data Factory (ADF) and Azure Synapse Analytics form a powerful combination for handling big data workloads in the cloud.
ADF enables data ingestion, transformation, and orchestration, while Azure Synapse provides high-performance analytics and data warehousing. Their integration supports massive-scale data processing, making them ideal for big data applications like ETL pipelines, machine learning, and real-time analytics. Key Aspects of ADF and Azure Synapse Integration for Big Data Processing
Data Ingestion at Scale ADF acts as the ingestion layer, allowing seamless data movement into Azure Synapse from multiple structured and unstructured sources, including: Cloud Storage: Azure Blob Storage, Amazon S3, Google
Cloud Storage On-Premises Databases: SQL Server, Oracle, MySQL, PostgreSQL Streaming Data Sources: Azure Event Hubs, IoT Hub, Kafka
SaaS Applications: Salesforce, SAP, Google Analytics 🚀 ADF’s parallel processing capabilities and built-in connectors make ingestion highly scalable and efficient.
2. Transforming Big Data with ETL/ELT ADF enables large-scale transformations using two primary approaches: ETL (Extract, Transform, Load): Data is transformed in ADF’s Mapping Data Flows before loading into Synapse.
ELT (Extract, Load, Transform): Raw data is loaded into Synapse, where transformation occurs using SQL scripts or Apache Spark pools within Synapse.
🔹 Use Case: Cleaning and aggregating billions of rows from multiple sources before running machine learning models.
3. Scalable Data Processing with Azure Synapse Azure Synapse provides powerful data processing features: Dedicated SQL Pools: Optimized for high-performance queries on structured big data.
Serverless SQL Pools: Enables ad-hoc queries without provisioning resources.
Apache Spark Pools: Runs distributed big data workloads using Spark.
💡 ADF pipelines can orchestrate Spark-based processing in Synapse for large-scale transformations.
4. Automating and Orchestrating Data Pipelines ADF provides pipeline orchestration for complex workflows by: Automating data movement between storage and Synapse.
Scheduling incremental or full data loads for efficiency. Integrating with Azure Functions, Databricks, and Logic Apps for extended capabilities.
⚙️ Example: ADF can trigger data processing in Synapse when new files arrive in Azure Data Lake.
5. Real-Time Big Data Processing ADF enables near real-time processing by: Capturing streaming data from sources like IoT devices and event hubs. Running incremental loads to process only new data.
Using Change Data Capture (CDC) to track updates in large datasets.
📊 Use Case: Ingesting IoT sensor data into Synapse for real-time analytics dashboards.
6. Security & Compliance in Big Data Pipelines Data Encryption: Protects data at rest and in transit.
Private Link & VNet Integration: Restricts data movement to private networks.
Role-Based Access Control (RBAC): Manages permissions for users and applications.
🔐 Example: ADF can use managed identity to securely connect to Synapse without storing credentials.
Conclusion
The integration of Azure Data Factory with Azure Synapse Analytics provides a scalable, secure, and automated approach to big data processing.
By leveraging ADF for data ingestion and orchestration and Synapse for high-performance analytics, businesses can unlock real-time insights, streamline ETL workflows, and handle massive data volumes with ease.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Step-by-Step Guide to AIOps Platform Development for Enterprises
As IT infrastructures become more complex, enterprises are increasingly turning to AIOps (Artificial Intelligence for IT Operations) platforms to streamline operations, enhance efficiency, and proactively manage incidents. A well-developed AIOps platform can automate troubleshooting, reduce downtime, and optimize IT performance using AI and machine learning.

In this blog, we’ll take you through a step-by-step guide to AIOps platform development for enterprises, covering everything from planning and data integration to model deployment and continuous optimization.
Step 1: Define Business Goals and Requirements
Before starting AIOps platform development, enterprises must clearly define objectives and align them with business needs. Key considerations include:
What IT challenges need to be solved? (e.g., downtime reduction, anomaly detection, performance optimization)
What metrics will define success? (e.g., Mean Time to Resolution (MTTR), system uptime, cost savings)
What existing IT tools and processes need integration?
A collaborative approach involving IT teams, data scientists, and business stakeholders ensures alignment between AIOps capabilities and enterprise goals.
Step 2: Choose the Right AIOps Architecture
The AIOps platform should be designed with scalability, flexibility, and real-time processing in mind. A typical AIOps architecture consists of:
1. Data Collection Layer
Collects data from logs, metrics, traces, and event streams
Integrates with IT monitoring tools (e.g., Splunk, Datadog, Prometheus)
2. Data Processing & Normalization
Cleans and structures raw data to prepare it for analysis
Eliminates redundant, outdated, and irrelevant data
3. AI & Machine Learning Models
Uses anomaly detection, predictive analytics, and event correlation algorithms
Applies natural language processing (NLP) for automated log analysis
4. Automation & Remediation Layer
Implements self-healing capabilities through automation scripts
Provides recommendations or auto-remediation for IT incidents
5. Visualization & Reporting
Dashboards and reports for monitoring insights
Custom alerts for proactive issue resolution
By selecting the right cloud-based, on-premises, or hybrid architecture, enterprises ensure scalability and flexibility.
Step 3: Data Integration & Collection
AIOps thrives on real-time, high-quality data from multiple sources. The platform should ingest data from:
IT infrastructure monitoring tools (Nagios, Zabbix)
Application performance monitoring (APM) tools (New Relic, AppDynamics)
Network monitoring tools (SolarWinds, Cisco DNA)
Cloud services (AWS CloudWatch, Azure Monitor)
💡 Best Practice: Use streaming data pipelines (Kafka, Apache Flink) for real-time event processing.
Step 4: Implement AI/ML Models for Analysis
The core of an AIOps platform is its AI-driven analysis. Enterprises should develop and deploy models for:
1. Anomaly Detection
Identifies abnormal patterns in system behavior using unsupervised learning
Helps detect issues before they escalate
2. Event Correlation & Noise Reduction
Uses graph-based analysis to correlate alerts from different sources
Filters out noise and reduces alert fatigue
3. Predictive Analytics
Forecasts potential failures using time-series forecasting models
Helps IT teams take preventive action
4. Incident Root Cause Analysis (RCA)
Uses AI-based pattern recognition to identify root causes
Reduces mean time to detect (MTTD) and mean time to resolve (MTTR)
💡 Best Practice: Continuously train and refine models using historical and real-time data for higher accuracy.
Step 5: Implement Automation & Self-Healing Capabilities
The true power of AIOps comes from its ability to automate responses and remediation. Enterprises should:
Automate routine IT tasks like server restarts, patch updates, and log cleanup
Use AI-driven playbooks for common incident resolution
Implement closed-loop automation where AI detects issues and applies fixes automatically
💡 Example: If an AIOps system detects high memory usage on a server, it can automatically restart specific processes without human intervention.
Step 6: Develop Dashboards & Alerts for Monitoring
To provide IT teams with real-time insights, enterprises must develop intuitive dashboards and alerting systems:
Use Grafana, Kibana, or Power BI for visualization
Set up dynamic alert thresholds using AI to prevent false positives
Enable multi-channel notifications (Slack, Teams, email, SMS)
💡 Best Practice: Implement explainable AI (XAI) to provide transparent insights into why alerts are triggered.
Step 7: Test, Deploy, and Optimize
After development, the AIOps platform should be rigorously tested for:
Scalability: Can it handle large data volumes?
Accuracy: Are AI models correctly identifying anomalies?
Latency: Is the system responding in real-time?
After successful testing, deploy the platform in stages (pilot → phased rollout → full deployment) to minimize risks.
💡 Best Practice: Implement a feedback loop where IT teams validate AI recommendations and continuously improve models.
Step 8: Continuous Learning and Improvement
AIOps is not a one-time setup—it requires continuous monitoring and optimization:
Retrain AI models regularly with new datasets
Refine automation workflows based on performance feedback
Incorporate user feedback to improve accuracy and usability
💡 Best Practice: Schedule quarterly AIOps audits to ensure efficiency and alignment with business goals.
Conclusion
Developing an AIOps platform for enterprises requires a structured, step-by-step approach—from goal setting and data integration to AI model deployment and automation. When implemented correctly, AIOps can enhance IT efficiency, reduce downtime, and enable proactive incident management.
0 notes
Text
Datanets for AI Development: A Guide to Selecting the Right Data Architecture
Discover the key considerations for selecting the right data architecture for AI development in our guide to Datanets.

In the world of AI development, data is the cornerstone. From training machine learning models to powering predictive analytics, high-quality and well-structured data is essential for building intelligent AI systems. However, as the volume and variety of data continue to grow, businesses face the challenge of selecting the right data architecture one that not only supports efficient data collection, processing, and storage, but also aligns with AI development goals.
Datanets the interconnected networks of data sources and storage systems play a crucial role in modern AI projects. These data architectures streamline data access, integration, and analysis, making it easier to extract valuable insights and build scalable AI models.
This guide will walk you through datanets for AI development and help you make informed decisions when selecting the ideal data architecture for your AI-driven projects.
What Are Datanets in AI Development?
Datanets refer to interconnected data sources, data storage systems, data pipelines, and data integration tools that work together to collect, process, store, and analyze large volumes of data efficiently. These data networks facilitate data flow across multiple platforms—whether cloud-based environments or on-premises systems—making it possible to access diverse datasets in real-time for AI model training and predictive analysis.
In AI development, datanets help in centralizing and streamlining data processes, which is vital for developing machine learning models, optimizing algorithms, and extracting actionable insights.
Key Components of a DataNet for AI
A datanet consists of several key components that work together to create a robust data architecture for AI development. These components include:
Data Sources: Structured (databases, spreadsheets), unstructured (images, videos, audio), and semi-structured (JSON, XML)
Data Storage: Cloud storage (AWS S3, Azure Blob Storage), distributed storage systems (HDFS, BigQuery)
Data Processing: Data pipelines (Apache Kafka, AWS Data Pipeline), data streaming (Apache Flink, Google Dataflow)
Data Integration Tools: ETL (Extract, Transform, Load) tools (Talend, Informatica), data integration platforms (Fivetran, Apache NiFi)
Data Analytics and Visualization: Data analysis tools (Tableau, Power BI), AI models (TensorFlow, PyTorch)
Benefits of Using Datanets in AI Development
Datanets offer several benefits that are critical for successful AI development. These advantages help businesses streamline data workflows, increase data accessibility, and improve model performance:
Efficient Data Flow: Datanets enable seamless data movement across multiple sources and systems, ensuring smooth data integration.
Scalability: Datanets are designed to scale with the growing data needs of AI projects, handling large volumes of data efficiently.
Real-Time Data Access: Datanets provide real-time data access for machine learning models, allowing instantaneous data analysis and decision-making.
Enhanced Data Quality: Datanets include data cleaning and transformation processes, which help improve data accuracy and model training quality.
Cost Efficiency: Datanets optimize data storage and processing, reducing the need for excessive human intervention and expensive infrastructure.
Collaboration: Datanets enable collaboration between teams by sharing datasets across different departments or geographical locations.
Factors to Consider When Selecting the Right Data Architecture
When selecting the right data architecture for AI development, several key factors must be taken into account to ensure the data net is optimized for AI. Here are the most important considerations:
Data Volume and Variety: AI models thrive on large and diverse datasets. The data architecture must handle big data, multi-source integration, and real-time data updates.
Data Integration and Accessibility: The data architecture should facilitate easy data access across multiple systems and applications—whether cloud-based, on-premises, or hybrid.
Scalability and Performance: An ideal data architecture should scale with growing data demands while ensuring high performance in processing and storage.
Security and Compliance: Data security and regulatory compliance (GDPR, CCPA, HIPAA) are critical factors in selecting a data architecture for AI-driven insights.
Data Quality and Cleaning: Data quality is essential for accurate model training. A good data architecture should incorporate data cleaning and transformation tools.
Best Practices for Designing a DataNet for AI Development
Designing an efficient DataNet for AI development involves best practices that ensure data flow optimization and model accuracy. Here are some key strategies:
Use a Centralized Data Repository: Create a central hub where all data is stored and accessible.
Implement Data Pipelines: Build data pipelines to automate data ingestion, transformation, and processing.
Leverage Cloud Infrastructure: Utilize cloud-based storage and computing for scalability and cost efficiency.
Ensure Data Quality Control: Incorporate data cleaning tools and validation processes to improve data accuracy.
Optimize for Real-Time Access: Design your data architecture for real-time data access and analysis.
Monitor Data Usage: Regularly monitor data access, integrity, and usage to ensure compliance and performance.
The Future of Data Architecture in AI Development
As AI technology advances, data architecture will continue to evolve. Future trends will focus on more decentralized data ecosystems, enhanced data interoperability, and increased use of AI-driven data insights. The integration of blockchain with AI for data security and trust will also gain prominence.
Conclusion
Selecting the right data architecture—using datanets—is crucial for successful AI development. It ensures efficient data integration, scalability, security, and accuracy in model training. By following best practices, addressing common challenges, and considering key factors, businesses can create a robust data architecture that supports their AI projects and drives business success.
As AI technologies evolve, datanets will remain a key component in scalable data management and intelligent decision-making. Whether it’s collecting large datasets, integrating data sources, or optimizing workflows, a well-designed DataNet is the foundation for leveraging AI to its fullest potential.
1 note
·
View note
Text
Big Data Meets Machine Learning: Exploring Advanced Data Science Applications
Introduction
The combination of Big Data and Machine Learning is changing industries and expanding opportunities in today's data-driven society. With the increase in data volumes and complexity, advanced data science is essential to converting this data into insights that can be put to use. Big Data's enormous potential combined with machine learning's capacity for prediction is transforming industries including healthcare, banking, and retail. This article examines how these technologies work together and provides examples of practical uses that show how Advanced Data Science can be used to tackle difficult problems.
How Big Data Enhances Machine Learning
1. Leveraging Massive Datasets for Model Accuracy
Big Data offers the enormous volumes of data required to build reliable models, and machine learning thrives on data. These datasets are tailored for machine learning algorithms thanks to advanced data science approaches including feature selection, dimensionality reduction, and data pretreatment. Businesses use this synergy to increase the accuracy of applications such as consumer segmentation, fraud detection, and personalized suggestions. Businesses can now find previously unattainable patterns because of the capacity to examine large datasets.
2. Real-Time Analytics with Streaming Data
Real-time analytics, made possible by the marriage of Big Data and Machine Learning, is revolutionary for sectors that need quick insights. Data scientists can process streaming data and quickly implement machine learning models with the help of sophisticated tools like Apache Kafka and Spark Streaming. This capacity is commonly used in industries such as logistics for delivery route optimization, healthcare for patient monitoring, and e-commerce for dynamic pricing. Data-driven and fast judgments are guaranteed by real-time data analytics.
3. Scalability and Distributed Learning
The scalability of big data and machine learning's requirement for processing power complement each other well. With the help of distributed frameworks like Hadoop and TensorFlow, data scientists can handle large datasets without sacrificing performance by training models across clusters. This scalability is advantageous for advanced data science applications, such as risk assessment in banking and predictive maintenance in manufacturing. Distributed learning guarantees that models can efficiently adjust to increasing data quantities.
Applications of Advanced Data Science in Big Data and Machine Learning
4. Predictive Analytics for Business Optimization
Businesses may anticipate future trends with the help of predictive analytics, which is fueled by big data and machine learning. Retailers utilize it to improve consumer experiences, optimize inventory, and estimate demand. It helps with portfolio management and credit rating in the financial industry. Organizations may keep ahead of market developments and make well-informed decisions by using past data to predict outcomes.
5. Personalized Customer Experiences
Highly customized consumer interactions are made possible by the combination of machine learning and big data. Sophisticated recommendation systems examine user behavior to make pertinent product or service recommendations using techniques like collaborative filtering and neural networks. This technology is used by online education providers, e-commerce companies, and streaming platforms to increase customer pleasure and engagement. Customization exemplifies how data-driven innovation can revolutionize an industry.
6. Fraud Detection and Security
One of the most important uses of advanced data science in the digital age is fraud detection. Machine learning algorithms can detect possible threats in real time by searching through massive databases for abnormalities and odd patterns. These models are used by cybersecurity companies and financial institutions to protect sensitive data and transactions. Across sectors, the combination of Big Data and Machine Learning improves security and reduces risk.
Conclusion
New horizons in advanced data science are being opened by the combination of big data and machine learning. Their combined potential revolutionizes how companies function and innovate, from real-time decision-making to predictive analytics. Gaining proficiency in these technologies and completing Advanced Data Science training programs are essential for those looking to take the lead in this field. Take part in the revolution influencing the direction of technology by enrolling in a program now to investigate the intersection of Big Data and Machine Learning.
0 notes
Text
Building Real-Time Data Pipelines: Key Tools and Best Practices
As the demand for immediate insights grows across industries, real-time data pipelines are essential in modern data engineering. Unlike batch processing, which handles data at scheduled intervals, real-time pipelines process data continuously, enabling organizations to respond instantly to new information and events. Constructing these pipelines effectively requires the right tools, approaches, and industry best practices. Timely insights can be delivered by data engineers who can build robust, real-time data pipelines that deliver the insights effectively.
Choosing the Right Tools for Real-Time Data Processing
Building a real-time pipeline starts with selecting tools that can handle high-speed data ingestion and processing. Apache Kafka, a popular event streaming platform, manages vast amounts of data by distributing messages across multiple brokers, making it scalable. For stream processing, tools like Apache Flink and Spark Structured Streaming process data with low latency. Combining these tools allows data engineers to build flexible, adaptive pipelines that support complex processing requirements. Seamless integration between these tools reduces development time and ensures smooth data flow, allowing engineers to deliver value faster.
Defining Data Transformation and Processing Stages
After data ingestion, the next step is transforming it into a usable format. Real-time pipelines require transformations that clean, filter, and enrich data in motion. Tools like Apache Beam and AWS Lambda offer flexible options for real-time transformation. Apache Beam’s unified model works across systems like Flink and Spark, simplifying scalable transformations. Defining clear processing stages, such as aggregating for analytics or filtering for anomaly detection, ensures data is processed accurately for real-time delivery to users or applications. With these stages in place, engineers can optimize data flow at every step.
Ensuring Data Quality and Reliability
In real-time systems, data quality is critical, as errors can quickly compound. Data engineers should incorporate automated validation and error-handling mechanisms to maintain quality. Tools like Great Expectations enable customizable data validation, while Apache Druid offers real-time data monitoring. Error-handling strategies, such as retries and dead-letter queues, allow the pipeline to continue even if certain inputs fail. Managing data quality prevents errors from affecting downstream applications, ensuring insights remain accurate. These measures are crucial for maintaining trust in the pipeline’s outputs.
Monitoring and Optimizing Pipeline Performance
Monitoring ensures that real-time data pipelines run smoothly. Tools like Prometheus and Grafana track pipeline performance, measuring latency, throughput, and resource use. This helps engineers identify bottlenecks early on, such as ingestion slowdowns or increased processing loads. Optimizing performance may involve adjusting resources, fine-tuning partitioning, or scaling resources based on demand. Proactive monitoring and optimization keep data moving efficiently, reducing delays and improving responsiveness. Continuous performance checks enable data engineers to meet evolving business needs with ease.
Building Effective Real-Time Data Pipelines for Added Efficiency
Creating efficient real-time data pipelines requires a strategic approach to data ingestion, processing, and monitoring. By leveraging tools like Apache Kafka, Flink, and Great Expectations, data engineers can build high-quality pipelines for real-time insights. Web Age Solutions provides specialized real-time data engineering courses, helping professionals build responsive data pipelines and enabling organizations to remain agile and data-driven in today’s fast-paced landscape.
For more information visit: https://www.webagesolutions.com/courses/data-engineering-training
0 notes
Text
AI, ML, and Big Data: What to Expect from Advanced Data Science Training in Marathahalli
AI, ML, and Big Data: What to Expect from Advanced Data Science Training in Marathahalli
Data science has emerged as one of the most critical fields in today’s tech-driven world. The fusion of Artificial Intelligence (AI), Machine Learning (ML), and Big Data analytics has changed the landscape of businesses across industries. As industries continue to adopt data-driven strategies, the demand for skilled data scientists, particularly in emerging hubs like Marathahalli, has seen an exponential rise.
Institutes in Marathahalli are offering advanced training in these crucial areas, preparing students to be future-ready in the fields of AI, ML, and Big Data. Whether you are seeking Data Science Training in Marathahalli, pursuing a Data Science Certification Marathahalli, or enrolling in a Data Science Bootcamp Marathahalli, these courses are designed to provide the hands-on experience and theoretical knowledge needed to excel.
AI and Machine Learning: Transforming the Future of Data Science
Artificial Intelligence and Machine Learning are at the forefront of modern data science. Students enrolled in AI and Data Science Courses in Marathahalli are introduced to the core concepts of machine learning algorithms, supervised and unsupervised learning, neural networks, deep learning, and natural language processing (NLP). These are essential for creating systems that can think, learn, and evolve from data.
Institutes in Marathahalli offering AI and ML training integrate real-world applications and projects to make sure that students can translate theory into practice. A Machine Learning Course Marathahalli goes beyond teaching the mathematical and statistical foundations of algorithms to focus on practical applications such as predictive analytics, recommender systems, and image recognition.
Data Science students gain proficiency in Python, R, and TensorFlow for building AI-based models. The focus on AI ensures that graduates of Data Science Classes Bangalore are highly employable in AI-driven industries, from automation to finance.
Key topics covered include:
Supervised Learning: Regression, classification, support vector machines
Unsupervised Learning: Clustering, anomaly detection, dimensionality reduction
Neural Networks: Deep learning models like CNN, RNN, and GANs
Natural Language Processing (NLP): Text analysis, sentiment analysis, chatbots
Model Optimization: Hyperparameter tuning, cross-validation, regularization
By integrating machine learning principles with AI tools, institutes like Data Science Training Institutes Near Marathahalli ensure that students are not just skilled in theory but are also ready for real-world challenges.
Big Data Analytics: Leveraging Large-Scale Data for Business Insights
With the advent of the digital age, businesses now have access to enormous datasets that, if analyzed correctly, can unlock valuable insights and drive innovation. As a result, Big Data Course Marathahalli has become a cornerstone of advanced data science training. Students are taught to work with massive datasets using advanced technologies like Hadoop, Spark, and NoSQL databases to handle, process, and analyze data at scale.
A Big Data Course Marathahalli covers crucial topics such as data wrangling, data storage, distributed computing, and real-time analytics. Students are equipped with the skills to process unstructured and structured data, design efficient data pipelines, and implement scalable solutions that meet the needs of modern businesses. This hands-on experience ensures that they can manage data at the petabyte level, which is crucial for industries like e-commerce, healthcare, finance, and logistics.
Key topics covered include:
Hadoop Ecosystem: MapReduce, HDFS, Pig, Hive
Apache Spark: RDDs, DataFrames, Spark MLlib
Data Storage: NoSQL databases (MongoDB, Cassandra)
Real-time Data Processing: Kafka, Spark Streaming
Data Pipelines: ETL processes, data lake architecture
Institutes offering Big Data Course Marathahalli prepare students for real-time data challenges, making them skilled at developing solutions to handle the growing volume, velocity, and variety of data generated every day. These courses are ideal for individuals seeking Data Analytics Course Marathahalli or those wanting to pursue business analytics.
Python for Data Science: The Language of Choice for Data Professionals
Python has become the primary language for data science because of its simplicity and versatility. In Python for Data Science Marathahalli courses, students learn how to use Python libraries such as NumPy, Pandas, Scikit-learn, Matplotlib, and Seaborn to manipulate, analyze, and visualize data. Python’s ease of use, coupled with powerful libraries, makes it the preferred language for data scientists and machine learning engineers alike.
Incorporating Python into Advanced Data Science Marathahalli training allows students to learn how to build and deploy machine learning models, process large datasets, and create interactive visualizations that provide meaningful insights. Python’s ability to work seamlessly with machine learning frameworks like TensorFlow and PyTorch also gives students the advantage of building cutting-edge AI models.
Key topics covered include:
Data manipulation with Pandas
Data visualization with Matplotlib and Seaborn
Machine learning with Scikit-learn
Deep learning with TensorFlow and Keras
Web scraping and automation
Python’s popularity in the data science community means that students from Data Science Institutes Marathahalli are better prepared to enter the job market, as Python proficiency is a sought-after skill in many organizations.
Deep Learning and Neural Networks: Pushing the Boundaries of AI
Deep learning, a subfield of machine learning that involves training artificial neural networks on large datasets, has become a significant force in fields such as computer vision, natural language processing, and autonomous systems. Students pursuing a Deep Learning Course Marathahalli are exposed to advanced techniques for building neural networks that can recognize patterns, make predictions, and improve autonomously with exposure to more data.
The Deep Learning Course Marathahalli dives deep into algorithms like convolutional neural networks (CNN), recurrent neural networks (RNN), and reinforcement learning. Students gain hands-on experience in training models for image classification, object detection, and sequence prediction, among other applications.
Key topics covered include:
Neural Networks: Architecture, activation functions, backpropagation
Convolutional Neural Networks (CNNs): Image recognition, object detection
Recurrent Neural Networks (RNNs): Sequence prediction, speech recognition
Reinforcement Learning: Agent-based systems, reward maximization
Transfer Learning: Fine-tuning pre-trained models for specific tasks
For those seeking advanced knowledge in AI, AI and Data Science Course Marathahalli is a great way to master the deep learning techniques that are driving the next generation of technological advancements.
Business Analytics and Data Science Integration: From Data to Decision
Business analytics bridges the gap between data science and business decision-making. A Business Analytics Course Marathahalli teaches students how to interpret complex datasets to make informed business decisions. These courses focus on transforming data into actionable insights that drive business strategy, marketing campaigns, and operational efficiencies.
By combining advanced data science techniques with business acumen, students enrolled in Data Science Courses with Placement Marathahalli are prepared to enter roles where data-driven decision-making is key. Business analytics tools like Excel, Tableau, Power BI, and advanced statistical techniques are taught to ensure that students can present data insights effectively to stakeholders.
Key topics covered include:
Data-driven decision-making strategies
Predictive analytics and forecasting
Business intelligence tools: Tableau, Power BI
Financial and marketing analytics
Statistical analysis and hypothesis testing
Students who complete Data Science Bootcamp Marathahalli or other job-oriented courses are often equipped with both technical and business knowledge, making them ideal candidates for roles like business analysts, data consultants, and data-driven managers.
Certification and Job Opportunities: Gaining Expertise and Career Advancement
Data Science Certification Marathahalli programs are designed to provide formal recognition of skills learned during training. These certifications are recognized by top employers across the globe and can significantly enhance career prospects. Furthermore, many institutes in Marathahalli offer Data Science Courses with Placement Marathahalli, ensuring that students not only acquire knowledge but also have the support they need to secure jobs in the data science field.
Whether you are attending a Data Science Online Course Marathahalli or a classroom-based course, placement assistance is often a key feature. These institutes have strong industry connections and collaborate with top companies to help students secure roles in data science, machine learning, big data engineering, and business analytics.
Benefits of Certification:
Increased job prospects
Recognition of technical skills by employers
Better salary potential
Access to global job opportunities
Moreover, institutes offering job-oriented courses such as Data Science Job-Oriented Course Marathahalli ensure that students are industry-ready, proficient in key tools, and aware of the latest trends in data science.
Conclusion
The Data Science Program Marathahalli is designed to equip students with the knowledge and skills needed to thrive in the fast-evolving world of AI, machine learning, and big data. By focusing on emerging technologies and practical applications, institutes in Marathahalli prepare their students for a wide array of careers in data science, analytics, and AI. Whether you are seeking an in-depth program, a short bootcamp, or an online certification, there are ample opportunities to learn and grow in this exciting field.
With the growing demand for skilled data scientists, Data Science Training Marathahalli programs ensure that students are prepared to make valuable contributions to their future employers. From foundational programming to advanced deep learning and business analytics, Marathahalli offers some of the best data science courses that cater to diverse needs, making it an ideal destination for aspiring data professionals.
Hashtags:
#DataScienceTrainingMarathahalli #BestDataScienceInstitutesMarathahalli #DataScienceCertificationMarathahalli #DataScienceClassesBangalore #MachineLearningCourseMarathahalli #BigDataCourseMarathahalli #PythonForDataScienceMarathahalli #AdvancedDataScienceMarathahalli #AIandDataScienceCourseMarathahalli #DataScienceBootcampMarathahalli #DataScienceOnlineCourseMarathahalli #BusinessAnalyticsCourseMarathahalli #DataScienceCoursesWithPlacementMarathahalli #DataScienceProgramMarathahalli #DataAnalyticsCourseMarathahalli #RProgrammingForDataScienceMarathahalli #DeepLearningCourseMarathahalli #SQLForDataScienceMarathahalli #DataScienceTrainingInstitutesNearMarathahalli #DataScienceJobOrientedCourseMarathahalli
0 notes
Text
Best Data Engineering Courses Online in Chennai
In the ever-evolving field of technology, data engineering has become a cornerstone for businesses looking to leverage data for better decision-making and operational efficiency. As companies generate and manage vast amounts of data daily, the demand for skilled data engineers has skyrocketed. If you’re in Chennai and looking for the best online data engineering courses, Apex Online Training offers comprehensive programs tailored to meet the growing demand in this field.

This article explores why data engineering is an essential skill, what the Apex Online Training courses offer, and why they are the best option for learners in Chennai looking to upskill in this crucial domain.
Why Data Engineering?
Data engineering involves designing, building, and maintaining the architecture that enables organizations to process and analyze large-scale data. It is the backbone of modern data-driven operations, and professionals in this field are responsible for creating data pipelines, handling databases, and ensuring that data flows efficiently through systems. Key responsibilities include:
Building data pipelines: Ensuring seamless data collection, transformation, and loading (ETL).
Database management: Structuring databases for easy access and analysis.
Big data solutions: Working with tools like Hadoop, Spark, and cloud-based platforms to manage large datasets.
Data security: Implementing best practices to protect sensitive information.
With the exponential growth of data, businesses in sectors like finance, healthcare, e-commerce, and IT rely heavily on skilled data engineers. Chennai, being a major tech hub in India, offers a plethora of job opportunities for professionals in this domain.
Why Choose Apex Online Training?
Apex Online Training stands out as one of the best options for data engineering courses in Chennai for several reasons:
1. Comprehensive Curriculum
Apex Online Training's data engineering courses are designed to provide learners with in-depth knowledge and hands-on skills that are directly applicable in real-world scenarios. The curriculum covers a wide range of topics, ensuring that learners have a thorough understanding of both the fundamentals and advanced techniques in data engineering. The course structure includes:
Introduction to Data Engineering: Understanding the role and responsibilities of a data engineer.
Data Warehousing and ETL: Learning about data architecture, data warehousing solutions, and how to build efficient ETL pipelines.
Big Data Technologies: Gaining expertise in Hadoop, Spark, Kafka, and other big data tools.
Cloud Platforms: Exploring cloud-based data solutions like AWS, Azure, and Google Cloud.
SQL and NoSQL Databases: Mastering SQL databases (PostgreSQL, MySQL) and NoSQL databases (MongoDB, Cassandra) for effective data storage and management.
Data Modeling: Learning techniques to structure data for easy analysis and efficient querying.
Python and Programming: Understanding how to use Python, Java, and Scala for automating data processes.
2. Hands-On Learning
At Apex Online Training, theoretical knowledge is paired with practical experience. The program includes hands-on projects where learners work on real-world datasets, allowing them to build data pipelines, design data architectures, and solve practical challenges. The course also offers capstone projects that simulate real-world industry scenarios, ensuring students are job-ready upon completion.
3. Industry-Relevant Tools
The course at Apex Online Training integrates the latest industry tools and technologies. Whether it's using Apache Hadoop for managing big data, working with Spark for real-time processing, or exploring cloud platforms like AWS and Google Cloud, learners get a strong grasp of the tools used by top companies today. Additionally, learners also get exposure to data visualization tools like Tableau and Power BI, which are critical for presenting data insights effectively.
4. Expert Faculty
One of the most significant advantages of choosing Apex Online Training is access to highly experienced instructors. The faculty includes industry professionals and experts with years of experience in data engineering and related fields. Their real-world insights and guidance help students understand the practical challenges of the job, making them more prepared to handle actual data engineering tasks.
6. Job Assistance
Upon course completion, Apex Online Training offers career support to help students find data engineering roles in Chennai or elsewhere. This includes resume-building workshops, mock interviews, and networking opportunities with industry leaders. The job assistance program significantly enhances the employability of graduates, giving them a competitive edge in the job market.
The Importance of Data Engineering in Chennai’s Tech Ecosystem
Chennai is home to a thriving tech industry, with numerous multinational companies, startups, and IT firms operating in the city. The demand for data engineering professionals in sectors like software development, finance, healthcare, and e-commerce is continuously rising. Data engineers in Chennai often work with large datasets, setting up infrastructure for companies to extract actionable insights from their data.
What Makes the Apex Online Data Engineering Course the Best in Chennai?
Holistic Learning Approach: The blend of theoretical knowledge, practical applications, and hands-on projects makes the learning experience at Apex Online Training comprehensive and effective.
Industry Alignment: The curriculum is updated regularly to reflect the latest trends and technologies in data engineering, ensuring that learners are always equipped with the most relevant skills.
Affordable and Accessible: Compared to many other platforms, Apex Online Training offers high-quality education at a reasonable price, making it accessible to a broad audience.
Certification and Recognition: Upon completing the course, learners receive a recognized certification, which boosts their profile and employability in the competitive job market.
How to Get Started with Apex Online Training
If you're looking to start or advance your career in data engineering, enrolling in the Apex Online Training Data Engineering Course is the perfect first step. The program is tailored to meet the needs of both beginners and professionals, ensuring a smooth learning journey.
Enrollment is easy:
Visit the Apex Online Training website.
Explore the Data Engineering course offerings.
Sign up for a free consultation or demo to understand more about the course structure.
Enroll and start your journey toward becoming a skilled data engineer.
Conclusion
With the growing demand for data engineering professionals in Chennai and beyond, now is the perfect time to acquire the skills needed to thrive in this field. Apex Online Training offers one of the best online data engineering courses, blending industry-relevant knowledge, practical skills, and expert mentorship to help you succeed.
If you're based in Chennai and looking for an online course that fits your schedule, budget, and learning needs, look no further than Apex Online Training. Start your data engineering journey today and step into one of the most exciting and lucrative careers of the digital age!
For More Information
Website: https://www.apexonlinetraining.com
Contact No: +91 85001220107
Email: [email protected]
Address: #402, PSR Prime Towers, Gachibowli, Hyderabad, India
1 note
·
View note
Text
Boost AI Production With Data Agents And BigQuery Platform

Data accessibility can hinder AI adoption since so much data is unstructured and unmanaged. Data should be accessible, actionable, and revolutionary for businesses. A data cloud based on open standards, that connects data to AI in real-time, and conversational data agents that stretch the limits of conventional AI are available today to help you do this.
An open real-time data ecosystem
Google Cloud announced intentions to combine BigQuery into a single data and AI use case platform earlier this year, including all data formats, numerous engines, governance, ML, and business intelligence. It also announces a managed Apache Iceberg experience for open-format customers. It adds document, audio, image, and video data processing to simplify multimodal data preparation.
Volkswagen bases AI models on car owner’s manuals, customer FAQs, help center articles, and official Volkswagen YouTube videos using BigQuery.
New managed services for Flink and Kafka enable customers to ingest, set up, tune, scale, monitor, and upgrade real-time applications. Data engineers can construct and execute data pipelines manually, via API, or on a schedule using BigQuery workflow previews.
Customers may now activate insights in real time using BigQuery continuous queries, another major addition. In the past, “real-time” meant examining minutes or hours old data. However, data ingestion and analysis are changing rapidly. Data, consumer engagement, decision-making, and AI-driven automation have substantially lowered the acceptable latency for decision-making. The demand for insights to activation must be smooth and take seconds, not minutes or hours. It has added real-time data sharing to the Analytics Hub data marketplace in preview.
Google Cloud launches BigQuery pipe syntax to enable customers manage, analyze, and gain value from log data. Data teams can simplify data conversions with SQL intended for semi-structured log data.
Connect all data to AI
BigQuery clients may produce and search embeddings at scale for semantic nearest-neighbor search, entity resolution, semantic search, similarity detection, RAG, and recommendations. Vertex AI integration makes integrating text, photos, video, multimodal data, and structured data easy. BigQuery integration with LangChain simplifies data pre-processing, embedding creation and storage, and vector search, now generally available.
It previews ScaNN searches for large queries to improve vector search. Google Search and YouTube use this technology. The ScaNN index supports over one billion vectors and provides top-notch query performance, enabling high-scale workloads for every enterprise.
It is also simplifying Python API data processing with BigQuery DataFrames. Synthetic data can replace ML model training and system testing. It teams with Gretel AI to generate synthetic data in BigQuery to expedite AI experiments. This data will closely resemble your actual data but won’t contain critical information.
Finer governance and data integration
Tens of thousands of companies fuel their data clouds with BigQuery and AI. However, in the data-driven AI era, enterprises must manage more data kinds and more tasks.
BigQuery’s serverless design helps Box process hundreds of thousands of events per second and manage petabyte-scale storage for billions of files and millions of users. Finer access control in BigQuery helps them locate, classify, and secure sensitive data fields.
Data management and governance become important with greater data-access and AI use cases. It unveils BigQuery’s unified catalog, which automatically harvests, ingests, and indexes information from data sources, AI models, and BI assets to help you discover your data and AI assets. BigQuery catalog semantic search in preview lets you find and query all those data assets, regardless of kind or location. Users may now ask natural language questions and BigQuery understands their purpose to retrieve the most relevant results and make it easier to locate what they need.
It enables more third-party data sources for your use cases and workflows. Equifax recently expanded its cooperation with Google Cloud to securely offer anonymized, differentiated loan, credit, and commercial marketing data using BigQuery.
Equifax believes more data leads to smarter decisions. By providing distinctive data on Google Cloud, it enables its clients to make predictive and informed decisions faster and more agilely by meeting them on their preferred channel.
Its new BigQuery metastore makes data available to many execution engines. Multiple engines can execute on a single copy of data across structured and unstructured object tables next month in preview, offering a unified view for policy, performance, and workload orchestration.
Looker lets you use BigQuery’s new governance capabilities for BI. You can leverage catalog metadata from Looker instances to collect Looker dashboards, exploration, and dimensions without setting up, maintaining, or operating your own connector.
Finally, BigQuery has catastrophe recovery for business continuity. This provides failover and redundant compute resources with a SLA for business-critical workloads. Besides your data, it enables BigQuery analytics workload failover.
Gemini conversational data agents
Global organizations demand LLM-powered data agents to conduct internal and customer-facing tasks, drive data access, deliver unique insights, and motivate action. It is developing new conversational APIs to enable developers to create data agents for self-service data access and monetize their data to differentiate their offerings.
Conversational analytics
It used these APIs to create Looker’s Gemini conversational analytics experience. Combine with Looker’s enterprise-scale semantic layer business logic models. You can root AI with a single source of truth and uniform metrics across the enterprise. You may then use natural language to explore your data like Google Search.
LookML semantic data models let you build regulated metrics and semantic relationships between data models for your data agents. LookML models don’t only describe your data; you can query them to obtain it.
Data agents run on a dynamic data knowledge graph. BigQuery powers the dynamic knowledge graph, which connects data, actions, and relationships using usage patterns, metadata, historical trends, and more.
Last but not least, Gemini in BigQuery is now broadly accessible, assisting data teams with data migration, preparation, code assist, and insights. Your business and analyst teams can now talk with your data and get insights in seconds, fostering a data-driven culture. Ready-to-run queries and AI-assisted data preparation in BigQuery Studio allow natural language pipeline building and decrease guesswork.
Connect all your data to AI by migrating it to BigQuery with the data migration application. This product roadmap webcast covers BigQuery platform updates.
Read more on Govindhtech.com
#DataAgents#BigQuery#BigQuerypipesyntax#vectorsearch#BigQueryDataFrames#BigQueryanalytics#LookMLmodels#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Unlock the Power of Open Source Technologies with HawkStack
In today’s fast-evolving technological landscape, Open Source solutions have become a driving force for innovation and scalability. At HawkStack, we specialize in empowering businesses by leveraging the full potential of Open Source technologies, offering cutting-edge solutions, consulting, training, and certification.
The Open Source Advantage
Open Source technologies provide flexibility, cost-efficiency, and community-driven development, making them essential tools for businesses looking to grow in a competitive environment. HawkStack's expertise spans across multiple domains, allowing you to adopt, implement, and scale your Open Source strategy seamlessly.
Our Expertise Across Key Open Source Technologies
Linux Distributions We support a wide range of Linux distributions, including Ubuntu and CentOS, offering reliable platforms for both server and desktop environments. Our team ensures smooth integration, security hardening, and optimal performance for your systems.
Containers & Orchestration With Docker and Kubernetes, HawkStack helps you adopt containerization and microservices architecture, enhancing application portability, scalability, and resilience. Kubernetes orchestrates your applications, providing automated deployment, scaling, and management.
Web Serving & Data Solutions Our deep expertise in web serving technologies like NGINX and scalable data solutions like Elasticsearch and MongoDB enables you to build robust, high-performing infrastructures. These platforms are key to creating fast, scalable web services and data-driven applications.
Automation with Ansible Automation is the backbone of efficient IT operations. HawkStack offers hands-on expertise with Ansible, a powerful tool for automating software provisioning, configuration management, and application deployment, reducing manual efforts and operational overhead.
Emerging Technologies We are at the forefront of emerging technologies like Apache Kafka, TensorFlow, and OpenStack. Whether you're building real-time streaming platforms with Kafka, deploying machine learning models with TensorFlow, or exploring cloud infrastructure with OpenStack, HawkStack has the know-how to guide your journey.
Why Choose HawkStack?
At HawkStack, our mission is to empower businesses with Open Source solutions that are secure, scalable, and future-proof. From consulting and implementation to training and certification, we ensure your teams are well-equipped to navigate and maximize the potential of these innovations.
Ready to harness the power of Open Source? Explore our full range of services and solutions by visiting HawkStack.
Empower your business today with HawkStack — your trusted partner in Open Source technologies!
0 notes